Reaction Details Report a problem with these data
Report a problem with these data
Report a problem with these dataTarget
AP2-associated protein kinase 1
Ligand
BDBM13534
Substrate
n/a
Meas. Tech.
ChEMBL_774569 (CHEMBL1908786)
Kd
290±n/a nM
Citation
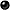 Davis, MI; Hunt, JP; Herrgard, S; Ciceri, P; Wodicka, LM; Pallares, G; Hocker, M; Treiber, DK; Zarrinkar, PP Comprehensive analysis of kinase inhibitor selectivity. Nat Biotechnol 29:1046-51 (2011) [PubMed] Article
Davis, MI; Hunt, JP; Herrgard, S; Ciceri, P; Wodicka, LM; Pallares, G; Hocker, M; Treiber, DK; Zarrinkar, PP Comprehensive analysis of kinase inhibitor selectivity. Nat Biotechnol 29:1046-51 (2011) [PubMed] Article More Info.:
Target
Name:
AP2-associated protein kinase 1
Synonyms:
AAK1 | AAK1_HUMAN | Adaptor-associated kinase 1 | KIAA1048
Type:
PROTEIN
Mol. Mass.:
103884.23
Organism:
Homo sapiens (Human)
Description:
ChEMBL_774569
Residue:
961
Sequence:
MKKFFDSRREQGGSGLGSGSSGGGGSTSGLGSGYIGRVFGIGRQQVTVDEVLAEGGFAIVFLVRTSNGMKCALKRMFVNNEHDLQVCKREIQIMRDLSGHKNIVGYIDSSINNVSSGDVWEVLILMDFCRGGQVVNLMNQRLQTGFTENEVLQIFCDTCEAVARLHQCKTPIIHRDLKVENILLHDRGHYVLCDFGSATNKFQNPQTEGVNAVEDEIKKYTTLSYRAPEMVNLYSGKIITTKADIWALGCLLYKLCYFTLPFGESQVAICDGNFTIPDNSRYSQDMHCLIRYMLEPDPDKRPDIYQVSYFSFKLLKKECPIPNVQNSPIPAKLPEPVKASEAAAKKTQPKARLTDPIPTTETSIAPRQRPKAGQTQPNPGILPIQPALTPRKRATVQPPPQAAGSSNQPGLLASVPQPKPQAPPSQPLPQTQAKQPQAPPTPQQTPSTQAQGLPAQAQATPQHQQQLFLKQQQQQQQPPPAQQQPAGTFYQQQQAQTQQFQAVHPATQKPAIAQFPVVSQGGSQQQLMQNFYQQQQQQQQQQQQQQLATALHQQQLMTQQAALQQKPTMAAGQQPQPQPAAAPQPAPAQEPAIQAPVRQQPKVQTTPPPAVQGQKVGSLTPPSSPKTQRAGHRRILSDVTHSAVFGVPASKSTQLLQAAAAEASLNKSKSATTTPSGSPRTSQQNVYNPSEGSTWNPFDDDNFSKLTAEELLNKDFAKLGEGKHPEKLGGSAESLIPGFQSTQGDAFATTSFSAGTAEKRKGGQTVDSGLPLLSVSDPFIPLQVPDAPEKLIEGLKSPDTSLLLPDLLPMTDPFGSTSDAVIEKADVAVESLIPGLEPPVPQRLPSQTESVTSNRTDSLTGEDSLLDCSLLSNPTTDLLEEFAPTAISAPVHKAAEDSNLISGFDVPEGSDKVAEDEFDPIPVLITKNPQGGHSRNSSGSSESSLPNLARSLLLVDQLIDL
Inhibitor
Name:
BDBM13534
Synonyms:
CHEMBL572878 | N-[4-({4-[(3-methyl-1H-pyrazol-5-yl)amino]-6-(4-methylpiperazin-1-yl)pyrimidin-2-yl}sulfanyl)phenyl]cyclopropanecarboxamide | N-[4-[[4-(4-methylpiperazino)-6-[(5-methyl-1H-pyrazol-3-yl)amino]pyrimidin-2-yl]thio]phenyl]cyclopropanecarboxamide | VX-680 | VX680 | cyclopropane carboxylic acid {4-[4-(4-methyl-piperazin-1-yl)-6-(5-methyl-2H-pyrazol-3-ylamino)-pyrimidin-2ylsulphanyl]-phenyl}-amide
Type:
Small organic molecule
Emp. Form.:
C23H28N8OS
Mol. Mass.:
464.586
SMILES:
CN1CCN(CC1)c1cc(Nc2cc(C)n[nH]2)nc(Sc2ccc(NC(=O)C3CC3)cc2)n1
Structure: