Reaction Details Report a problem with these data
Report a problem with these data
Report a problem with these dataTarget
Egl nine homolog 1/Prolyl hydroxylase EGLN2/Prolyl hydroxylase EGLN3/Transmembrane prolyl 4-hydroxylase
Ligand
BDBM50233538
Substrate
n/a
Meas. Tech.
ChEMBL_1909275 (CHEMBL4411721)
EC50
>50000±n/a nM
Citation
 Minassi, A; Rogati, F; Cruz, C; Prados, ME; Galera, N; Jin�nez, C; Appendino, G; Bellido, ML; Calzado, MA; Caprioglio, D; Mu�oz, E Triterpenoid Hydroxamates as HIF Prolyl Hydrolase Inhibitors. J Nat Prod 81:2235-2243 (2018) [PubMed] Article
Minassi, A; Rogati, F; Cruz, C; Prados, ME; Galera, N; Jin�nez, C; Appendino, G; Bellido, ML; Calzado, MA; Caprioglio, D; Mu�oz, E Triterpenoid Hydroxamates as HIF Prolyl Hydrolase Inhibitors. J Nat Prod 81:2235-2243 (2018) [PubMed] Article More Info.:
Target
Name:
Egl nine homolog 1/Prolyl hydroxylase EGLN2/Prolyl hydroxylase EGLN3/Transmembrane prolyl 4-hydroxylase
Synonyms:
Hypoxia-inducible factor prolyl hydroxylase
Type:
n/a
Mol. Mass.:
n/a
Description:
ASSAY_ID of ChEMBL is 1909275
Components:
This complex has 4 components.
Component 1
Name:
Prolyl hydroxylase EGLN2
Synonyms:
EGLN2 | EGLN2_HUMAN | EIT6 | Egl nine homolog 2 | Estrogen-induced tag 6 | HIF prolyl hydroxylase | HIF-PH1 | HIF-prolyl hydroxylase 1 | HPH-3 | Hypoxia-inducible factor prolyl hydroxylase | PHD1 | Prolyl hydroxylase domain-containing protein 1 | Prolyl hydroxylase domain-containing protein 1 (PHD1)
Type:
Protein
Mol. Mass.:
43657.01
Organism:
Homo sapiens (Human)
Description:
Q96KS0
Residue:
407
Sequence:
MDSPCQPQPLSQALPQLPGSSSEPLEPEPGRARMGVESYLPCPLLPSYHCPGVPSEASAGSGTPRATATSTTASPLRDGFGGQDGGELRPLQSEGAAALVTKGCQRLAAQGARPEAPKRKWAEDGGDAPSPSKRPWARQENQEAEREGGMSCSCSSGSGEASAGLMEEALPSAPERLALDYIVPCMRYYGICVKDSFLGAALGGRVLAEVEALKRGGRLRDGQLVSQRAIPPRSIRGDQIAWVEGHEPGCRSIGALMAHVDAVIRHCAGRLGSYVINGRTKAMVACYPGNGLGYVRHVDNPHGDGRCITCIYYLNQNWDVKVHGGLLQIFPEGRPVVANIEPLFDRLLIFWSDRRNPHEVKPAYATRYAITVWYFDAKERAAAKDKYQLASGQKGVQVPVSQPPTPT
Component 2
Name:
Transmembrane prolyl 4-hydroxylase
Synonyms:
Hypoxia-inducible factor prolyl 4-hydroxylase | Hypoxia-inducible factor prolyl hydroxylase | Hypoxia-inducible factor prolyl hydroxylase 4 | Hypoxia-inducible factor prolyl hydroxylase 4 (HIF) | P4HTM | P4HTM_HUMAN | PH4 | Transmembrane prolyl 4-hydroxylase
Type:
Enzyme
Mol. Mass.:
56654.25
Organism:
Homo sapiens (Human)
Description:
Q9NXG6
Residue:
502
Sequence:
MAAAAVTGQRPETAAAEEASRPQWAPPDHCQAQAAAGLGDGEDAPVRPLCKPRGICSRAYFLVLMVFVHLYLGNVLALLLFVHYSNGDESSDPGPQHRAQGPGPEPTLGPLTRLEGIKVGHERKVQLVTDRDHFIRTLSLKPLLFEIPGFLTDEECRLIIHLAQMKGLQRSQILPTEEYEEAMSTMQVSQLDLFRLLDQNRDGHLQLREVLAQTRLGNGWWMTPESIQEMYAAIKADPDGDGVLSLQEFSNMDLRDFHKYMRSHKAESSELVRNSHHTWLYQGEGAHHIMRAIRQRVLRLTRLSPEIVELSEPLQVVRYGEGGHYHAHVDSGPVYPETICSHTKLVANESVPFETSCRYMTVLFYLNNVTGGGETVFPVADNRTYDEMSLIQDDVDLRDTRRHCDKGNLRVKPQQGTAVFWYNYLPDGQGWVGDVDDYSLHGGCLVTRGTKWIANNWINVDPSRARQALFQQEMARLAREGGTDSQPEWALDRAYRDARVEL
Component 3
Name:
Egl nine homolog 1
Synonyms:
C1orf12 | EGLN1 | EGLN1_HUMAN | Egl nine homolog 1 (EGLN1) | Hypoxia-inducible factor prolyl hydroxylase 2 (HIF-PH2) | Hypoxia-inducible factor prolyl hydroxylase 2 (HIFPH2) | Prolyl hydroxylase domain-containing protein 2 (PHD2)
Type:
Protein
Mol. Mass.:
46035.59
Organism:
Homo sapiens (Human)
Description:
Q9GZT9
Residue:
426
Sequence:
MANDSGGPGGPSPSERDRQYCELCGKMENLLRCSRCRSSFYCCKEHQRQDWKKHKLVCQGSEGALGHGVGPHQHSGPAPPAAVPPPRAGAREPRKAAARRDNASGDAAKGKVKAKPPADPAAAASPCRAAAGGQGSAVAAEAEPGKEEPPARSSLFQEKANLYPPSNTPGDALSPGGGLRPNGQTKPLPALKLALEYIVPCMNKHGICVVDDFLGKETGQQIGDEVRALHDTGKFTDGQLVSQKSDSSKDIRGDKITWIEGKEPGCETIGLLMSSMDDLIRHCNGKLGSYKINGRTKAMVACYPGNGTGYVRHVDNPNGDGRCVTCIYYLNKDWDAKVSGGILRIFPEGKAQFADIEPKFDRLLFFWSDRRNPHEVQPAYATRYAITVWYFDADERARAKVKYLTGEKGVRVELNKPSDSVGKDVF
Component 4
Name:
Prolyl hydroxylase EGLN3
Synonyms:
EGLN3 | EGLN3_HUMAN | Egl nine homolog 3 (EGLIN3) | Egl nine homolog 3 (EGLN3)
Type:
Protein
Mol. Mass.:
27265.54
Organism:
Homo sapiens (Human)
Description:
Q9H6Z9
Residue:
239
Sequence:
MPLGHIMRLDLEKIALEYIVPCLHEVGFCYLDNFLGEVVGDCVLERVKQLHCTGALRDGQLAGPRAGVSKRHLRGDQITWIGGNEEGCEAISFLLSLIDRLVLYCGSRLGKYYVKERSKAMVACYPGNGTGYVRHVDNPNGDGRCITCIYYLNKNWDAKLHGGILRIFPEGKSFIADVEPIFDRLLFFWSDRRNPHEVQPSYATRYAMTVWYFDAEERAEAKKKFRNLTRKTESALTED
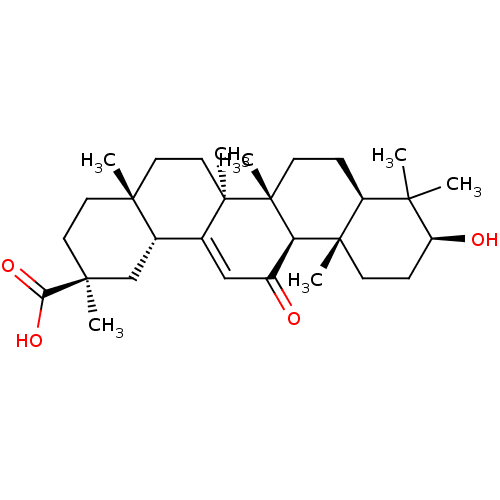
Inhibitor
Name:
BDBM50233538
Synonyms:
18beta-glycyrrhetic acid | 3beta-hydroxy-11-oxoolean-12-en-30-oic acid | CHEMBL230006 | US11660306, Example 18beta Glycyrrhetinic acid | glycyrrhetinic acid
Type:
Small organic molecule
Emp. Form.:
C30H46O4
Mol. Mass.:
470.6838
SMILES:
CC1(C)[C@@H](O)CC[C@@]2(C)[C@H]1CC[C@]1(C)[C@@H]2C(=O)C=C2[C@@H]3C[C@](C)(CC[C@]3(C)CC[C@@]12C)C(O)=O |r,t:19|
Structure: