Reaction Details Report a problem with these data
Report a problem with these data
Report a problem with these dataTarget
Histone-lysine N-methyltransferase EHMT2
Ligand
BDBM50346553
Substrate
n/a
Meas. Tech.
ChEMBL_752821 (CHEMBL1798506)
IC50
106±n/a nM
Citation
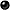
More Info.:
Target
Name:
Histone-lysine N-methyltransferase EHMT2
Synonyms:
BAT8 | C6orf30 | EHMT2 | EHMT2_HUMAN | G9A | G9a histone methyltransferase (G9A) | Histone-lysine N-methyltransferase EHMT1/EHMT2 | Histone-lysine N-methyltransferase, H3 lysine-9 specific 3 | KMT1C | NG36 | Protein G9a (G9a)
Type:
Enzyme
Mol. Mass.:
132339.87
Organism:
Homo sapiens (Human)
Description:
Q96KQ7
Residue:
1210
Sequence:
MAAAAGAAAAAAAEGEAPAEMGALLLEKETRGATERVHGSLGDTPRSEETLPKATPDSLEPAGPSSPASVTVTVGDEGADTPVGATPLIGDESENLEGDGDLRGGRILLGHATKSFPSSPSKGGSCPSRAKMSMTGAGKSPPSVQSLAMRLLSMPGAQGAAAAGSEPPPATTSPEGQPKVHRARKTMSKPGNGQPPVPEKRPPEIQHFRMSDDVHSLGKVTSDLAKRRKLNSGGGLSEELGSARRSGEVTLTKGDPGSLEEWETVVGDDFSLYYDSYSVDERVDSDSKSEVEALTEQLSEEEEEEEEEEEEEEEEEEEEEEEEDEESGNQSDRSGSSGRRKAKKKWRKDSPWVKPSRKRRKREPPRAKEPRGVNGVGSSGPSEYMEVPLGSLELPSEGTLSPNHAGVSNDTSSLETERGFEELPLCSCRMEAPKIDRISERAGHKCMATESVDGELSGCNAAILKRETMRPSSRVALMVLCETHRARMVKHHCCPGCGYFCTAGTFLECHPDFRVAHRFHKACVSQLNGMVFCPHCGEDASEAQEVTIPRGDGVTPPAGTAAPAPPPLSQDVPGRADTSQPSARMRGHGEPRRPPCDPLADTIDSSGPSLTLPNGGCLSAVGLPLGPGREALEKALVIQESERRKKLRFHPRQLYLSVKQGELQKVILMLLDNLDPNFQSDQQSKRTPLHAAAQKGSVEICHVLLQAGANINAVDKQQRTPLMEAVVNNHLEVARYMVQRGGCVYSKEEDGSTCLHHAAKIGNLEMVSLLLSTGQVDVNAQDSGGWTPIIWAAEHKHIEVIRMLLTRGADVTLTDNEENICLHWASFTGSAAIAEVLLNARCDLHAVNYHGDTPLHIAARESYHDCVLLFLSRGANPELRNKEGDTAWDLTPERSDVWFALQLNRKLRLGVGNRAIRTEKIICRDVARGYENVPIPCVNGVDGEPCPEDYKYISENCETSTMNIDRNITHLQHCTCVDDCSSSNCLCGQLSIRCWYDKDGRLLQEFNKIEPPLIFECNQACSCWRNCKNRVVQSGIKVRLQLYRTAKMGWGVRALQTIPQGTFICEYVGELISDAEADVREDDSYLFDLDNKDGEVYCIDARYYGNISRFINHLCDPNIIPVRVFMLHQDLRFPRIAFFSSRDIRTGEELGFDYGDRFWDIKSKYFTCQCGSEKCKHSAEAIALEQSRLARLDPHPELLPELGSLPPVNT
Inhibitor
Name:
BDBM50346553
Synonyms:
CHEMBL1797937
Type:
Small organic molecule
Emp. Form.:
C32H24F3N3O6
Mol. Mass.:
603.5447
SMILES:
COc1ccc(cc1)C(=O)Oc1ccc(CCn2c(NC(=O)c3ccc(cc3)C(F)(F)F)nc3cc(ccc23)C(O)=O)cc1
Structure: